Building an In-House Data Science Platform
Read and follow me on Medium (opens in a new tab)
In the realm of data-driven innovation, the creation of an in-house Data Science Platform (DSP) is a pivotal undertaking. This article delves into the core components and strategic considerations that constitute the foundation of this innovative powerhouse.
Understanding the Core Components
The in-house DSP is more than just a technological investment; it’s a strategic move to position the organization at the forefront of data-driven innovation. This centralized ecosystem is meticulously designed to enhance the end-to-end data science workflow, providing a collaborative space for data scientists, engineers, and analysts. Let’s explore the value embedded in each component:
Unlocking Value in Every Component
- Enhanced Collaboration and Efficiency: Centralizing configurations facilitates collaboration, allowing teams to script-manage RAM/CPU per Spark job. This ensures efficiency and seamless collaboration across the platform.
- Robust Security and Data Organization: Implementing sharing and permission structures, organizing file systems, and planning for the removal of root accounts contribute to a secure and organized data environment within the Linux system.
- Managing and Orchestrating Data Flow: Providing storage location recommendations, understanding implicit functions of computing resources like Airflow, and managing Google Cloud Storage (GCS) setup contribute to cost control and efficient data processes.
- Efficient File and Code Sharing: Establishing network-shared file systems, clarifying permissions, and integrating with GitLab for code sharing ensures smooth collaboration and knowledge transfer.
The Architectural Pillars
The success of our in-house data science platform hinges on the thoughtful selection and integration of key components. Let’s delve into these architectural pillars:
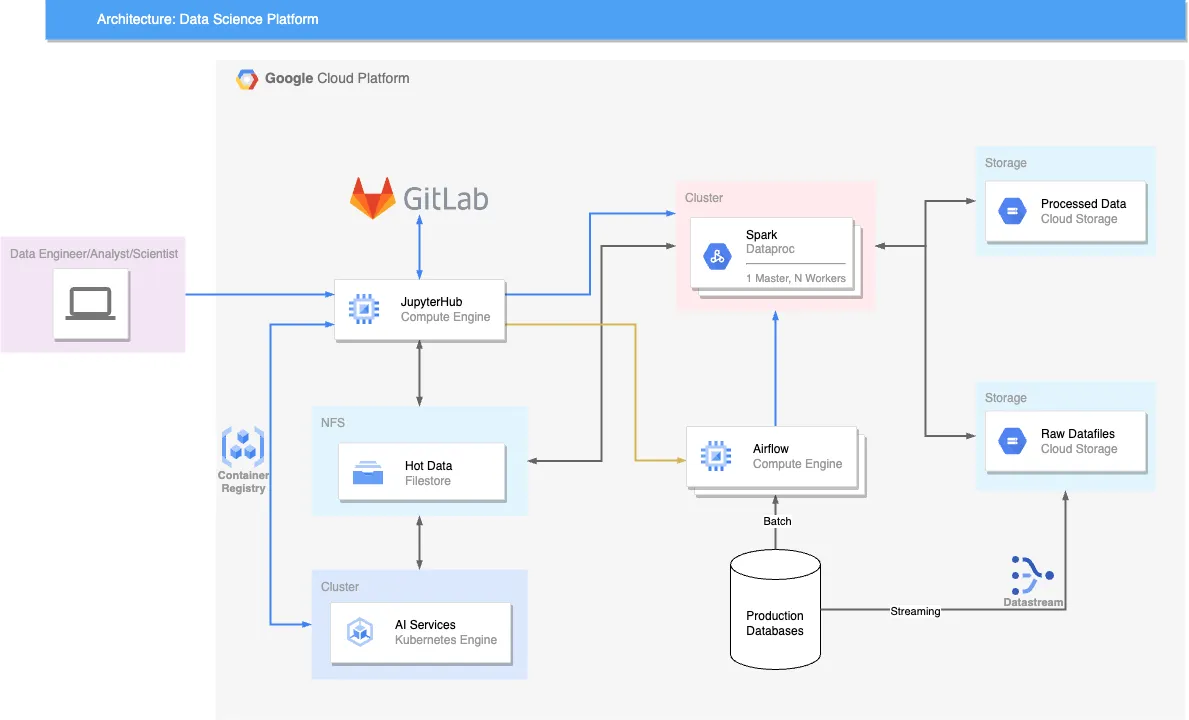
a. JupyterHub: Serving as the heart of collaborative and interactive computing, JupyterHub enables multiple users to access a shared environment for data exploration and analysis.
b. Apache Spark: As the backbone for distributed data processing, Apache Spark excels in handling large-scale data tasks, ensuring our platform can manage data-intensive applications effectively.
c. Google Cloud Storage (GCS): Providing scalable and secure object storage, GCS seamlessly integrates into our platform, ensuring efficient data storage, access, and retrieval.
d. GitLab: Version control is crucial for reproducibility and collaboration. GitLab acts as the repository for managing code changes, tracking versions, and fostering collaboration.
e. Kubernetes (K8s): Orchestrating containerized applications, Kubernetes ensures scalability and reliability. It simplifies the deployment of AI services and the management of machine learning models, making our platform production-ready.
f. Network File System (Filestore): NFS facilitates shared file access, promoting seamless collaboration and data sharing among team members.
g. Linux: The Linux operating system provides a stable and customizable environment for building and running data science applications.
h. IAM on GCP and Linux ACLs: IAM controls access to resources within the platform, maintaining data security in GCS. Additionally, Linux Access Control Lists (ACLs) offer a flexible permission mechanism for file systems.
Putting it All Together
Conclusion
In conclusion, the creation of an in-house Data Science Platform transcends a mere technological investment. It’s a strategic initiative that propels the organization to the forefront of data-driven innovation. By meticulously addressing specific requirements, ensuring practicality, and seamlessly integrating key components, the platform becomes a potent tool for collaborative exploration, experimentation with data, report creation, and machine learning model deployment. This positions data scientists, analysts, and engineers at the forefront of cutting-edge advancements in the field.