BigQuery resource management
Read and follow me on Medium (opens in a new tab)
“Good resource management results in the right resources being available at the right time for the right work”
Tiki (opens in a new tab) is one of the largest e-commerce companies in Vietnam and the highly complex data platform at Tiki is built in the cloud, with a rapidly growing number of batch workflows, real-time data pipelines, and distributed systems. The Data Platform team here has a mission to provide a real data platform that manages more data types and structures throughout Tiki, including not just data used for security, privacy, and compliance, but also technical and IT operations data — all data that Tikier imports or generates.
Currently, we have been developing a lakehouse system on Google Cloud Warehouse, BigQuery (opens in a new tab), which provides a serverless architecture that allows for fast queries due to parallel processing, as well as separate storage and compares for expandable processing and memory. At Tiki, according to the data we aggregated, the average volume of data processed on BigQuery is more than 300 TB of data and 2 million sessions per day. This number can be 3 to 4 times higher on days with big campaigns on Tiki app/website, such as 1/1, 2/2,…
At this scale, we needed to have a resource management mechanism in place for BigQuery that ensured the right allocation of resources to the right people at the right time. Our goal in this project is to optimize and allocate resources to the right workloads. By minimizing waste, and maximizing resources, we can provide the users of BigQuery at Tiki with the easiest and most optimized experience for their work.
Why not use Google Cloud Platform’s built-in Monitoring service or a 3rd party to manage resources?
Of course, we thought of this too, but after a few tests, we realized that Cloud Monitoring of Google Cloud Platform provides a better management mechanism for the activity of a group of resources, rather than on individual resources.
In fact, Google Cloud also provides another feature that can manage resources according to specific data, called Custom metrics. But with a large and increasing number of users, configuring each Custom metric for each user as Google does is very time-consuming and laborious.
Besides, we also research observability services for cloud-scale applications such as Datadog (opens in a new tab). But in order to secure data and develop many features specifically tailored to the needs of the team, we decided to build and develop our own resource management service. This project includes modules such as Monitoring, Alerting, and Resource Management, and is part of the data discovery in the Tiki. In this article, I will focus only on how we manage resources on Biquery.
Our solution
The idea is based on log-based metrics. But instead of using system-defined log-based metrics and relying on that to manage resources, we decided to use logs from Google’s Cloud Logging to create our own metrics.
To get logs related to BigQuery, Google Cloud provides a solution called Logs Router in Cloud Logging (opens in a new tab), which helps users to receive logs from Google services. We will use this feature to be able to transfer logs back to our messaging systems for specific project purposes, like Pubsub or Kafka.
From the input logs we receive, we will be able to generate precomputable metrics for monitoring and alerting. Regarding metrics, we have 2 main types of metrics:
- Counter metrics count the number of log entries matching a given filter.
- Distribution metrics accumulate numeric data from log entries matching a filter.
Also, we have a pretty special metric we call the up-time check. Served for alert policies to check the time-out of running jobs or queues.
To distribute resources, we design a service that can provide a limit to users on a certain type of resource, this service is organized in groups and can send requests to increase or decrease The limit is set when the need arises, of course, someone will have to approve this (in our case it will be the team leader).
After having the metrics and resource limit available, the remaining job is to track the user’s actions on BigQuery, and when the user uses excessive resources, we have alerting service to alerts and actions (like revoking the user’s permission).
Architecture
- Overview
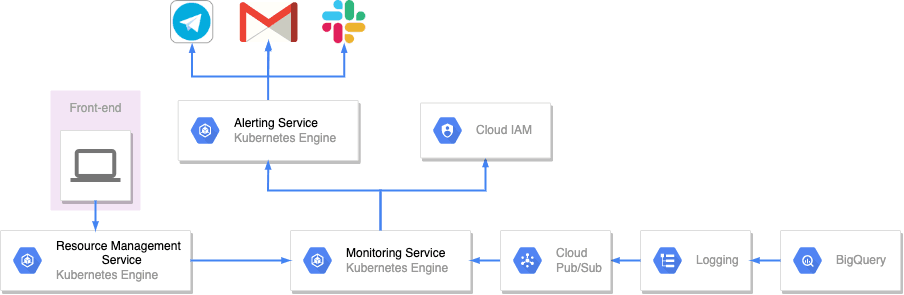
- Detail
For running jobs:
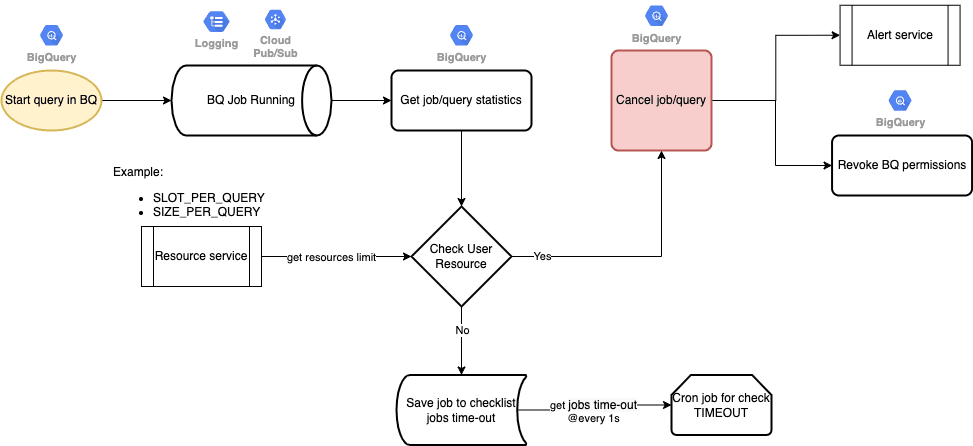
For completed jobs:
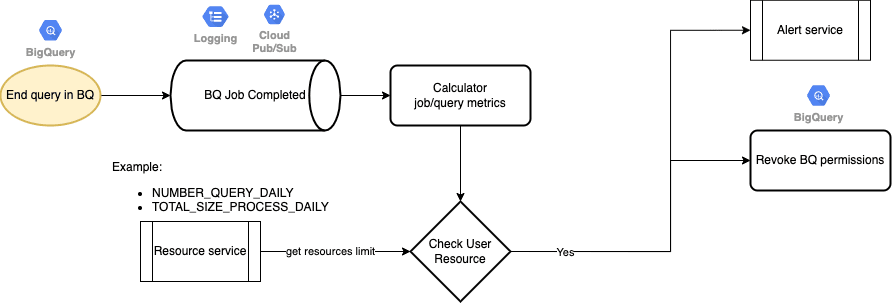
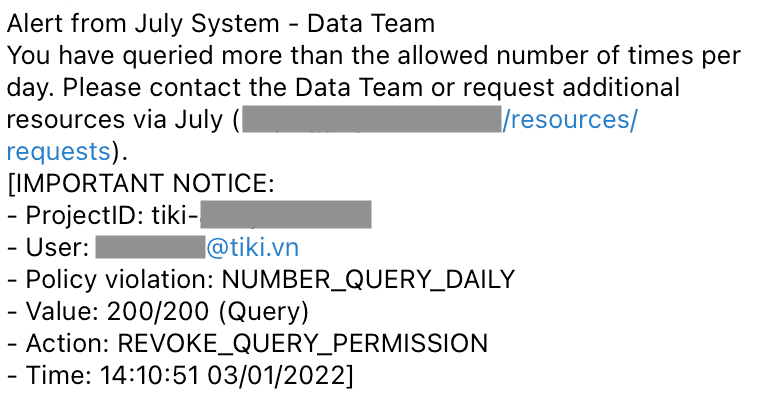
Alert message via Telegram (opens in a new tab):
What’s next?
The project has had a significant impact on the operability of the Tiki data platform. And helped engineering teams lower the burden of resource management work, freeing them to tackle more critical and challenging problems. But our job is nowhere near done. We have a long roadmap ahead of us. Some of the features and expansions we have planned are:
-
Reduce processing latency and take corrective action for jobs/queries that are being executed.
-
Dynamic-configure metrics to be able to configure more alert policies by UI.
-
Expand the project for monitoring more resource types.
-
Use Machine Learning to allocate resources to configure faster and use fewer resources when possible.
Acknowledgments
This work could not have been completed without the help of the Infrastructure teams within the Tiki Data Platform. They have been great partners for us as we work on improving the project infrastructure.