Storage Feature Engineering for real-time prediction in MoMo
Read and follow me on Medium (opens in a new tab)
At MoMo, we have many problems using machine learning models to optimize product performance for users. For example fraud detection, real-time product recommendation, churn prediction,… To store and access features so it’s much easier to name, organize, and reuse them across teams. We had to carefully select and design the architecture of the database to host these features.
Definition
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
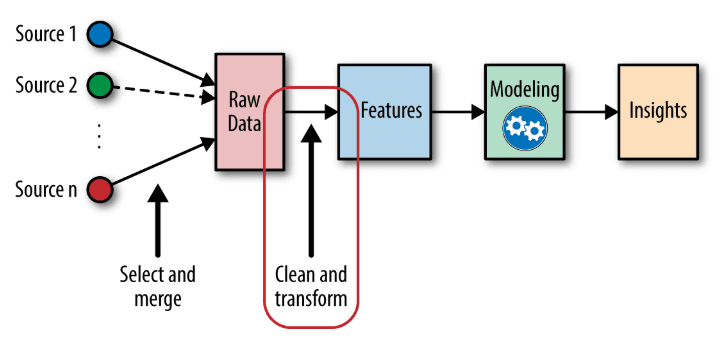
Data flow
However, feature engineering for batch and real-time is a very different story. The level of complexity in real-time feature engineering is much greater than for batch, and at the same time, the business demand for real-time use cases is growing rapidly.
Challenges
Feature engineering for real-time use cases is more complex than for batch. Real-time pipelines require an extremely fast event-processing mechanism that can run complex algorithms to calculate features in real-time.
With the growing business demand for real-time use cases such as fraud prediction, churn prediction, and building real-time product recommendation engines, ML Engineer/Data Scientist team in MoMo are feeling immense pressure to solve the operational challenges of real-time feature engineering for machine learning in a simple and reproducible way. In this post, I will revisit the concepts and the practices of building a database for real-time feature engineering to support this.
Storage
In summary, to store Feature Engineering for real-time prediction, a database is required a real-time database. For calculating events in real-time with strict performance requirements and built-in HA. This storage engine enables feature extraction in real-time and at scale. We’re going to use the Google Cloud Bigtable solution for this case.
Google Cloud Bigtable (opens in a new tab) is a massively scalable NoSQL database service engineered for high throughput and low-latency workloads. It can handle petabytes of data, with millions of reads and writes per second at a latency that’s on the order of milliseconds. The data is structured as a sorted key-value map. Bigtable scales linearly with the number of nodes.
Key features
- High throughput at low latency. Consistent sub-10ms latency — handle millions of requests per second.
- Flexible, automated replication to optimize any workload. Seamlessly scale to match your storage needs; no downtime during reconfiguration.
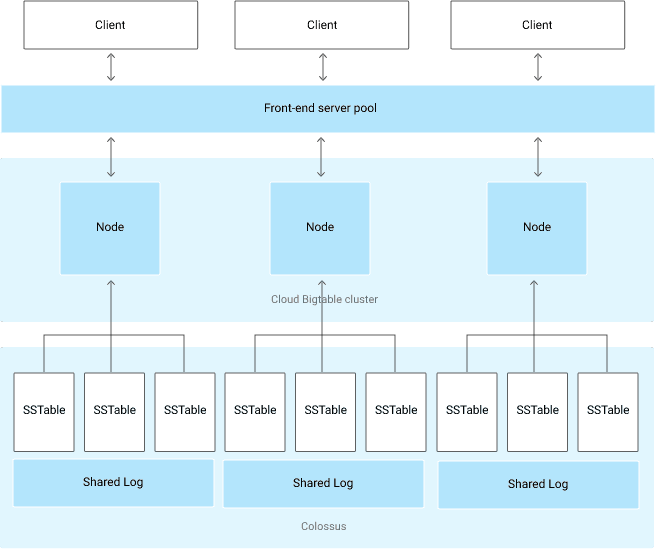
Bigtable’s overall architecture
BigTable is designed with semi-structured data storage in mind. It is a large map that is indexed by a row key, column key, and timestamp. Each value within the map is an array of bytes that is interpreted by the application. Every read or write of data to a row is atomic, regardless of how many different columns are read or written within that row.

Bigtable storage model
Implementation
Next, with the above outstanding features of Bigtable, we use it to store 2 data sets: Historical Data Table and Offline Features Table.
The idea is that when the model needs real-time prediction we will aggregate Historical Data and Offline Features to form Real-Time Features Engineering.

Feature Engineering in event-driven
To compute features over a long time, this work needs to be done in advance with a large amount of work, these features are stored in the Offline Features Table. For the model to be accessible to real-time data sources, it is important to provide the data source at the time it happened. Such data retrieval requires a continuous real-time data ingestion and save to Historical Data Table, it covers undetermined data in Offline Features.
The image below shows a simple way of storing and processing Real-Time Features Engineering.
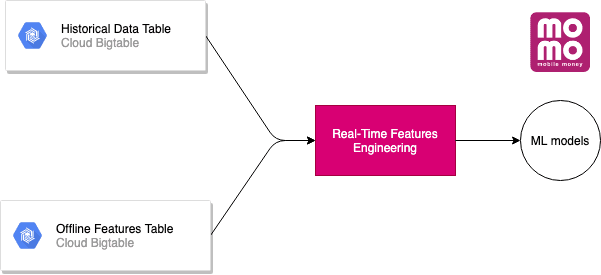
Architectural design brief
Offline Features Table is processed in batches every day. It’s transformed & calculated from the data on BigQuery (opens in a new tab) to BigTable. Features in this table are organized in a structure where a list of offline features will be permanently stored in a qualifier column.
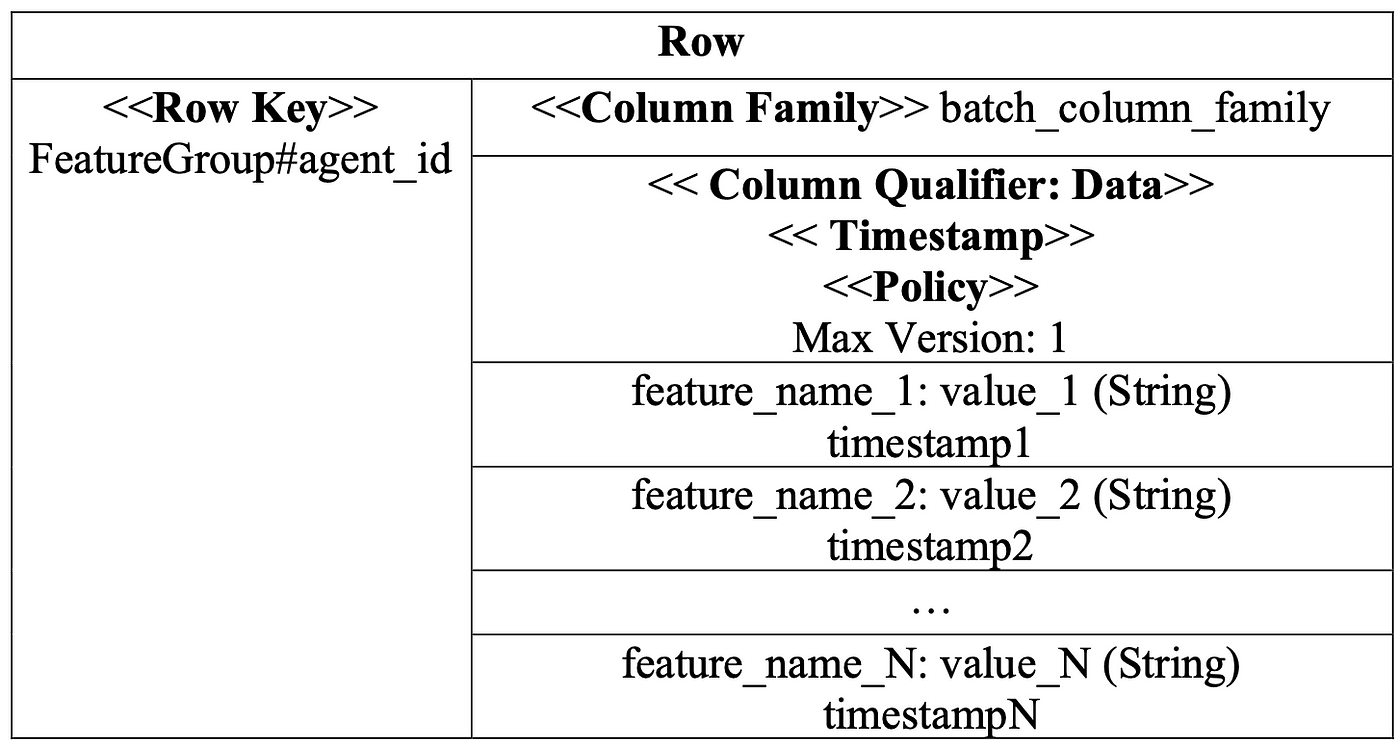
Offline Features Table schema
Historical Data Table records all the events which are processed from the streaming raw events. The event data in this table is organized according to the structure of each event with a column qualifier so that it is possible to quickly query a set of events at a certain time. In addition, the storage period of the column qualifier in this table is 180 days ~ 6 months, to save storage costs.
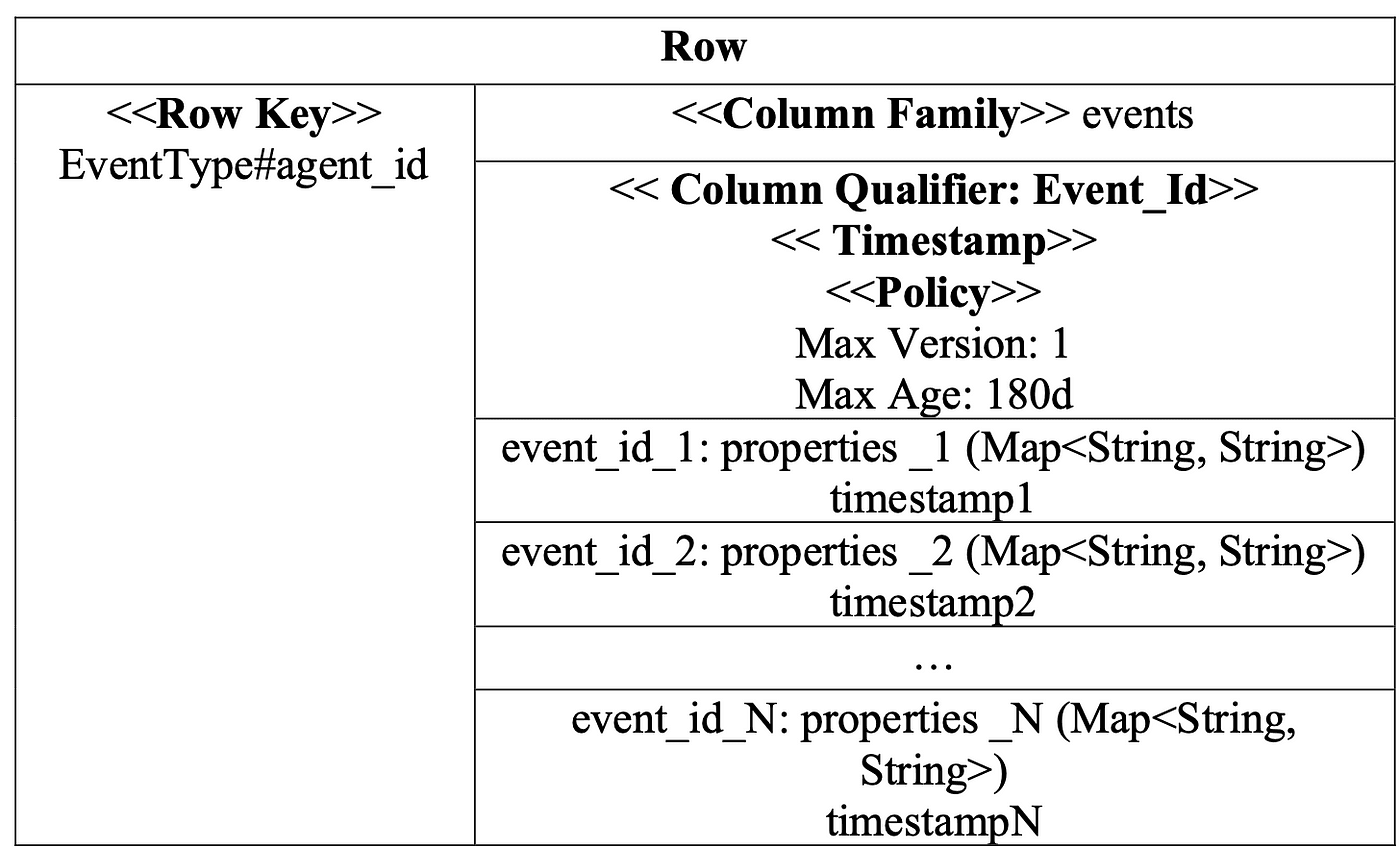
Historical Data Table schema
Conclusion
Real-time feature engineering is essential for any model’s real-time prediction. And Bigtable tools are useful for Data Scientists/Machine Learning Engineers to index when they need to move from batch to streaming workflows for building predictive models. By using Bigtable data stores, the latency in a workflow can be reduced from minutes or hours to just seconds, enabling ML models to use up-to-date inputs.